
Motivación
Desde que comenzó la "operación militar especial" de Rusia en Ucrania, he estado observando los comentarios en los live threads en el subreddit r/worldnews. Vi con asombro cómo la frecuencia de los comentarios aumentaba con cada acontecimiento importante, pero también noté cómo cada día había menos comentarios que mostraban una disminución sostenida del interés (al menos cuando se mide por los comentarios de Reddit) sobre el tema de la invasión.
Esto me motivó a buscar todos los live threads en un intento de averiguar si mi percepción era cierta o no. Los dos siguientes posts son el resultado de esta curiosidad; en el primero (el que estás leyendo ahora) te mostraré cómo creé el conjunto de datos, mientras que en el segundo, encontrarás cómo utilizar los datos.
La API de Reddit
Hay un par de formas de descargar datos de Internet: el web scraping o las APIs (cuando están disponibles): el web scraping es mi favorito, pero al mismo tiempo, el que más tiempo consume y el más frágil de mantener, ya que cualquier cambio en el diseño hace que tu scraping se vuelva loco.
Por suerte para nosotros, Reddit ofrece una API que se puede utilizar para consumir datos del sitio.
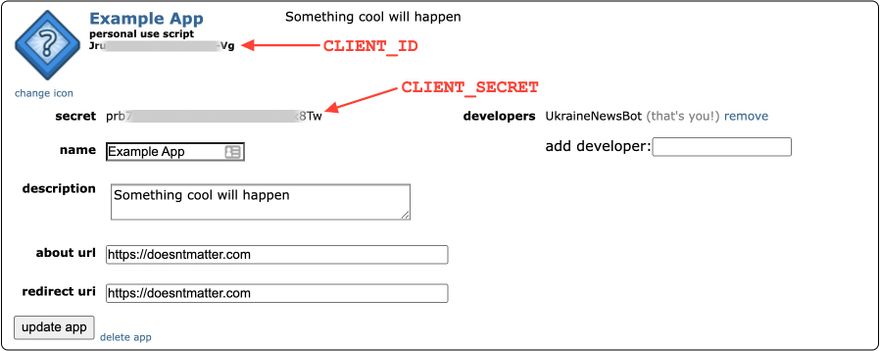
Al igual que con la mayoría de las APIs de los sitios web más importantes, para empezar a usar esta api, uno necesita registrar una aplicación - mi recomendación es que crees una cuenta de Reddit completamente diferente, ya que también tendrás que usar la contraseña de dicha cuenta para autenticarte.
Cuando tu aplicación haya sido creada, toma nota de los siguientes valores ya que los usaremos también:
Usando PRAW para consumir la API
Para consumir la API a través de Python, utilizaremos el paquete PRAW. Se puede instalar mediante Python con pip install praw.
Una vez que tenemos nuestro id de cliente y nuestro secreto podemos pasar a crear una instancia de praw.Reddit pasando la información que acabamos de obtener de Reddit; para evitar la codificación de nuestra contraseña y secretos vamos a utilizar variables de entorno para establecer estos valores:
reddit = praw.Reddit(
client_id=os.environ["CLIENT_ID"],
client_secret=os.environ["CLIENT_SECRET"],
password=os.environ["PASSWORD"],
user_agent="Live Thread Scraper by UkraineNewsBot",
username="UkraineNewsBot",
)
Función de hasheo
Utilizaremos una función que toma una cadena y la desordena de manera determinista, esto es para "enmascarar" algunos valores que no creo que deban hacerse públicos, o al menos, no tan fácilmente.
def hash_string(content):
return hashlib.md5(content.encode()).hexdigest()
Encontrando todos los hilos
Necesitamos encontrar todos los live threads relacionados con la invasión, por lo que limitaré la búsqueda a que comience a partir del 1 de febrero de 2022 (no hay hilos anteriores a febrero) y termine un día antes de ejecutar la búsqueda:
begin_point = datetime(2022, 2, 1)
today = datetime.utcnow().replace(hour=0, minute=0, second=0, microsecond=0) - timedelta(hours=12)
A continuación defino una lista de moderadores de r/worldnews, ya que son los únicos que pueden crear hilos vivos. La lista de mods se puede obtener utilizando la propia API:
mods = [
# Mod list
]
Iterando sobre cada usuario
La única forma que he encontrado para encontrar todos los hilos es peinar todos los posts realizados por los mods y luego averiguar cuáles pertenecen a lo que nos interesa aquí. El siguiente fragmento de código hace eso, recuperando hasta 200 threads por usuario y almacenándolos en una lista:
subs = []
for username in mods:
user = reddit.redditor(name=username)
for post in user.submissions.new(limit=200):
subs.append(post)
Iterando sobre cada thread
Una vez que tenemos todos los threads realizados por los moderadores, podemos iterar sobre ellos en busca de los que queremos. En este caso, los que queremos empiezan por "/r/worldnews live thread", "r/worldnews live thread" o "worldnews live thread" y fueron realizados entre el 1 de febrero y ayer.
Por último, para extraer todas las propiedades, estoy utilizando la función getattr en combinación con una lista de propiedades.
properties = [
"id", "created_utc", "name", "num_comments",
"permalink", "score", "title", "upvote_ratio"
]
def extract_submission_props(post):
post_props = [post.author.name]
post_props.extend([getattr(post, pr) for pr in properties])
return post_props
submissions = []
for post in subs:
title_low = post.title.lower()
if (
title_low.startswith("/r/worldnews live thread")
or title_low.startswith("r/worldnews live thread")
or title_low.startswith("worldnews live thread")
) and begin_point.timestamp() < post.created_utc < today.timestamp():
submissions.append(extract_submission_props(post))
Conversión a DataFrame
Una vez que tenemos todos los envíos en una lista, debemos convertirla a un DataFrame de pandas para que sea fácil trabajar con ella y guardarla:
live_threads = pd.DataFrame(submissions, columns=["author"] + properties)
Luego entonces podemos:
- Usar
pd.to_datetimepara convertir el timestamp unix en una fecha real - Hacer un hash del nombre del autor con la función
hash_stringdeclarada anteriormente
live_threads["created_at"] = pd.to_datetime(live_threads["created_utc"], unit="s", origin="unix")
live_threads["author"] = live_threads["author"].apply(hash_string)
Por último, es el momento de guardar los datos del hilo con un orden especificado en las columnas, ordenados por fecha de creación y sin índice:
live_threads[["id", "name", "author", "title", "created_utc", "created_at", "num_comments", "score", "upvote_ratio", "permalink"]].sort_values(
"created_utc", ascending=True
).to_csv("data/threads.csv", index=False)
Descargando TODOS los comentarios de un TODOS los hilos
El siguiente paso es bastante sencillo. Tenemos que iterar sobre el fichero que acabamos de crear y utilizar el paquete PRAW para descargar todos los comentarios realizados en un thread.
Para empezar, vamos a crear una función que tome un comentario y un identificador de cada thread y devuelva una lista de sus propiedades, esta función es un poco más compleja dado que los comentarios difieren unos de otros. Una vez más, estoy usando la función getattr para hacernos la vida más fácil.
comment_props = [
"id", "body", "edited",
"created_utc", "link_id",
"parent_id", "distinguished",
"depth", "ups", "downs", "score",
"total_awards_received", "gilded",
]
def extract_comment(comment, submission_id):
if comment.author:
cmmt = [hash_string(comment.author.name), submission_id]
else:
cmmt = [None, submission_id]
cmmt.extend([getattr(comment, prop) for prop in comment_props])
if comment.gildings:
gildings = str(comment.gildings)
else:
gildings = None
cmmt.append(gildings)
return cmmt
Ya tenemos todo listo para iterar sobre los hilos descargando todos los que aún no tenemos. Hay un tutorial en el propio sitio web de PRAW que detalla cómo descargar los comentarios en un hilo - hay un poco de personalización en términos de convertir todo a un DataFrame, pero el código en sí es bastante auto-explicativo:
for submission_id in live_threads["id"]:
file_name = f"data/comments/comments__{submission_id}.csv"
if os.path.exists(file_name):
continue
submission = reddit.submission(id=submission_id)
submission.comments.replace_more(limit=1)
comments = []
for comment in submission.comments.list():
comments.append(extract_comment(comment, submission_id))
frame = pd.DataFrame(comments, columns=["author", "submission_id"] + comment_props + ["gildings"])
frame.to_csv(file_name, index=False)
Automatizando todo con GitHub Actions
Todos los días se crean nuevos hilos, lo que significa que si queremos mantener actualizado nuestro conjunto de datos, también debemos ejecutar este script todos los días. Si mantienes tu código en GitHub, ya tienes el candidato perfecto para la automatización con GitHub Actions.
En primer lugar, necesitaremos guardar nuestras variables de entorno con secretos (CLIENT_ID, CLIENT_SECRET, PASSWORD) como secretos del repositorio. Para hacer esto, vaya a Configuración ➡ Secretos (Acciones) ➡ Nuevo secreto de repositorio:

Una vez que tengas todos los secretos disponibles, crea un archivo .yml en el directorio .github/workflows.
name: Download dataset
on:
schedule:
- cron: "0 10 * * *"
jobs:
process:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v2
with:
python-version: "3.8"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install pipenv
pipenv install --system --dev
- name: Download dataset from Reddit
env:
CLIENT_ID: ${{ secrets.CLIENT_ID }}
CLIENT_SECRET: ${{ secrets.CLIENT_SECRET }}
PASSWORD: ${{ secrets.PASSWORD }}
run: python download_threads.py
- name: Commit changes
run: |
git config --global user.email "antonio.feregrino@gmail.com"
git config --global user.name "Antonio Feregrino"
git add data/
git diff --quiet && git diff --staged --quiet || git commit -m "Updated: `date +'%Y-%m-%d %H:%M'`"
git push
En corto, el código de arriba se ejecuta todos los días a las 10 AM y hace:
- Le hace el checkout al código
- Instala Python 3.8
- Instala las dependencias, yo estoy usando Pipenv para gestionarlas
- Ejecuta todo el código de la descarga de datos que hicimos en este post
- Crea un commit con los cambios al repositorio, guardando los archivos CSV creados
Conclusión
Y eso es todo, ahora hemos descargado todos los hilos relevantes, y estamos listos para usarlos.
En este post, hemos echado un vistazo a cómo crear un conjunto de datos utilizando los datos de Reddit, y en el próximo, mostraré cómo utilizar este conjunto de datos para crear algo interesante; espero que hayas aprendido algo nuevo o al menos que te haya gustado.
Para terminar, el código está disponible aquí junto con todo el repositorio y el dataset ya está disponible en Kaggle. Como siempre, estoy abierto a responder cualquier pregunta en Twitter en @feregri_no.

Discussion (0)